
ぜひ、研究や仕事でなどでお使いください。@しばた
目次
- 資料を作るとき
- 論文を読む・調べるとき
- プライマーを作るとき
- DNA配列を収集・調べるとき
- 学名を和名にしたいとき
- 環境DNAのデータを解析したいとき
資料を作る
Illumina製の機器・技術のイメージ
Miseq使った実験後にいい感じの報告書を作成する際に使用します。無料登録すれば誰でも使用可能です。
論文を読む・調べる
Taylor Wilcox HP

不定期で環境DNAの論文一覧PDFと論文数のグラフが更新されます。
時々、論文の見逃しがないかを確認するのに使ってます。
The detection of aquatic macroorganisms using environmental DNA analysis—A review of methods for collection, extraction, and detection

2018年までの環境DNAのトレンドをレビューした論文です。Support informationのエクセルファイルにそれまでの論文一覧が乗っています。
ちょっとした宣伝も含んでますが、何かキーワードで検索すると便利なデータになっていると思います。
もちろん内容も水棲の大型脊椎動物を対象に行われている環境DNAを用いた調査の方法をちゃんとレビューしています。
DeepL & shaper

論文を溜めて、まとめてさっと読みたい時に使います。
DeepLは皆さんご存知の翻訳アプリです。shaperは論文の本文をコピペして翻訳機にかけるとき、よく挟まる改行など消して体裁を整えてくれます。
今まではテキストエディタと正規表現でやってましたが、ブラウザを開いたままサクサク出来るので重宝しています。
プライマーを作る・調べる
Primer Blast
プライマーの特異性(ターゲット生物のみを増幅できるか)の確認に使います。また、Tm値、プライマー配列の自己相補性(Self-Complementary)の確認などにも使います。
使い方は統合TVを参考にしていただくか、ここでもそのうち簡単な解説をするのでそれをおまちください。
DNA配列を収集・調べる
NCBI
アメリカ国立生物工学情報センター(NCBI)のDNA・アミノ酸・プロテインなどの統合データベースです。
目的の生物の配列は登録されているかを検索したり、配列をダウンロードするのに使います。
最近はpythonにはまっており、プライマーを作る時に必要な複数種・複数領域の配列ダウンロードは黒い画面で使うBiopythonのEntrezを使ってます。
学名を和名にする
鹿児島大学総合研究博物館 日本産魚類全種目録

以前こちらで紹介した、日本産魚類の和名・学名の対応表です。記事内の加工したエクセルシートが使いやすくていいと思います。
環境DNAのデータを解析する
潮雅之さんのブログ

Rを使った解析時にどのように解析データを整理すればいいか、また進めていくべきかが書かれている記事や、rEDMを使った時系列解析に関する解説記事があります。
いつもデータが取っ散らかる私でも、型があると整理できます。
水産研究・教育機構 日本海区水産研究所
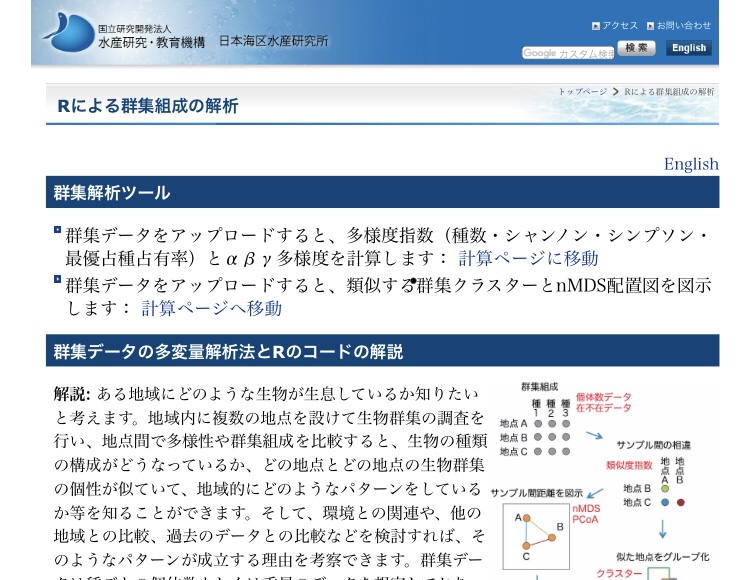
群集解析を行いたい時にどんな解析ができるのか、実データとともに解説してくれています。もちろん、環境DNAもおおよそデータの質は同じなので適用可能です。
多用度指数の比較、非計量多次元尺度法:NMDS、指標種解析、調査地点のクラスタリングなど、取り組みやすい難易度の群集解析ができます。
もちろん群集解析に関するベースとなる知識は必要ですが、手を動かしてみるという段階にはとてもありがたいサイトです。
また、Rが動かせなくても地点×種の形になったcsvファイルがあればweb上で解析できます。
MiFish pipeline

MiFishプライマーを使ったライブラリ調整の後のシーケンスファイル(Fastq.gzファイル)が手元にあるなら”Get Started Now”を押して解析してみましょう。
1,2サンプルであればすぐ解析は終わります。解説はこちらもでしてます。
ざっと思いつくものを載せました。また更新します。





